Two employees at the same company use the same AI copilot every day. Both show up as "active users" in the adoption dashboard.
One gets clear, usable answers on the first try. The other rephrases three times, abandons the conversation, and emails a colleague instead.
The adoption metric is identical. The experience is completely different.
Adoption tells you who showed up. Fluency tells you who got value.
Every company deploying AI internally tracks adoption. It is the first metric everyone reaches for, and it makes sense as a starting point. But adoption is a binary: someone used the tool, or they didn't. It says nothing about whether the interaction was productive.
AI fluency is the next layer. It measures the quality of the interaction between a person and an AI tool. Did the employee get a useful result? How efficiently did they get there? Did the conversation resolve their question, or did they give up and find the answer somewhere else?
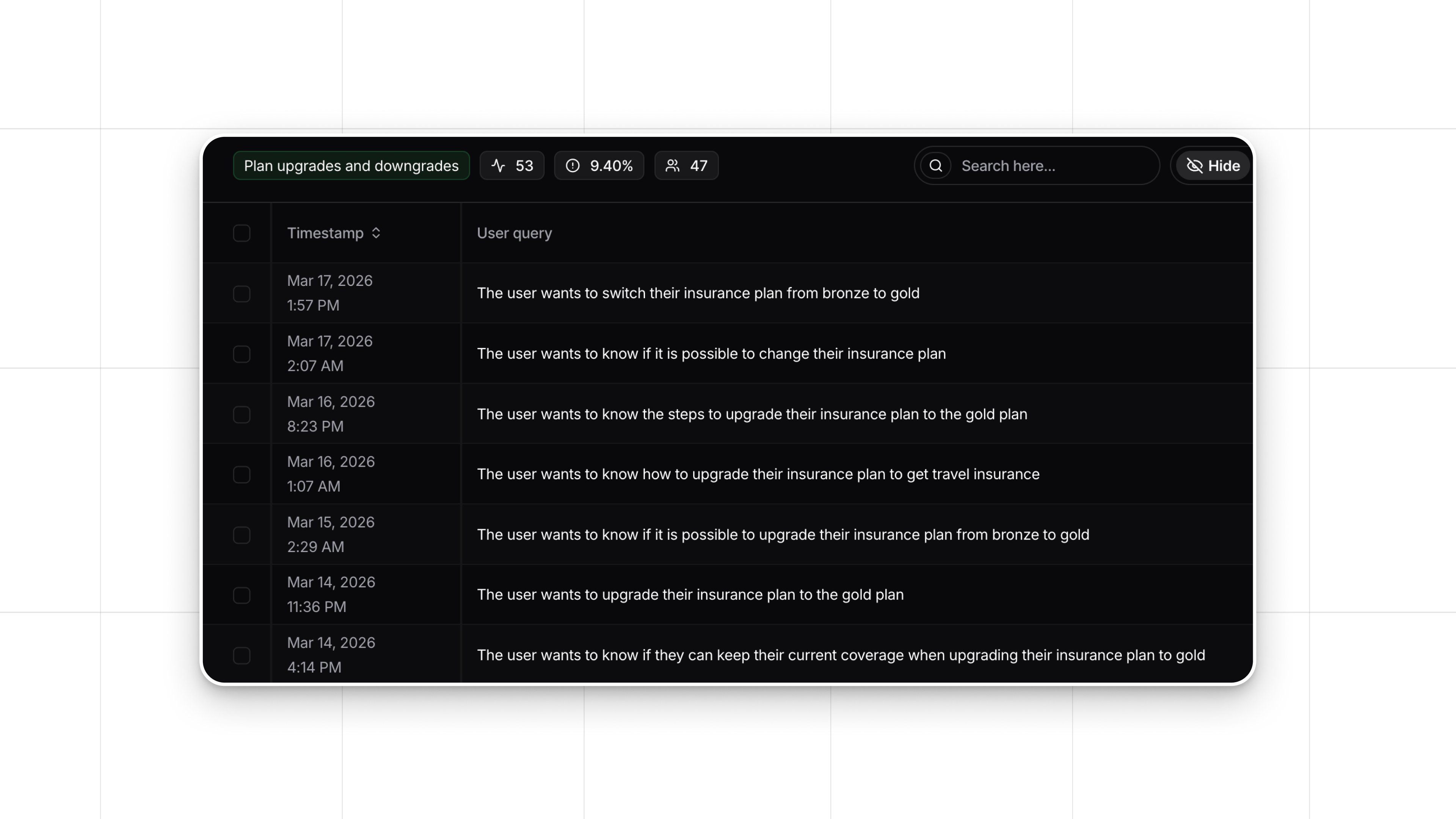
These are observable patterns. They show up in behavioral signals within the conversation itself, what we call implicit feedback: rephrasing (the first answer wasn't useful), abandonment (the user gave up), quick task completion (the tool worked well), prompt specificity (the user knows how to ask). Implicit feedback reveals the quality of the experience without surveys, self-reporting, or anyone watching over someone's shoulder.
AI Fluency Index turns those signals into something teams can act on
AI Fluency Index in Nebuly reads these implicit feedback signals across every employee AI conversation and turns them into a fluency measure.
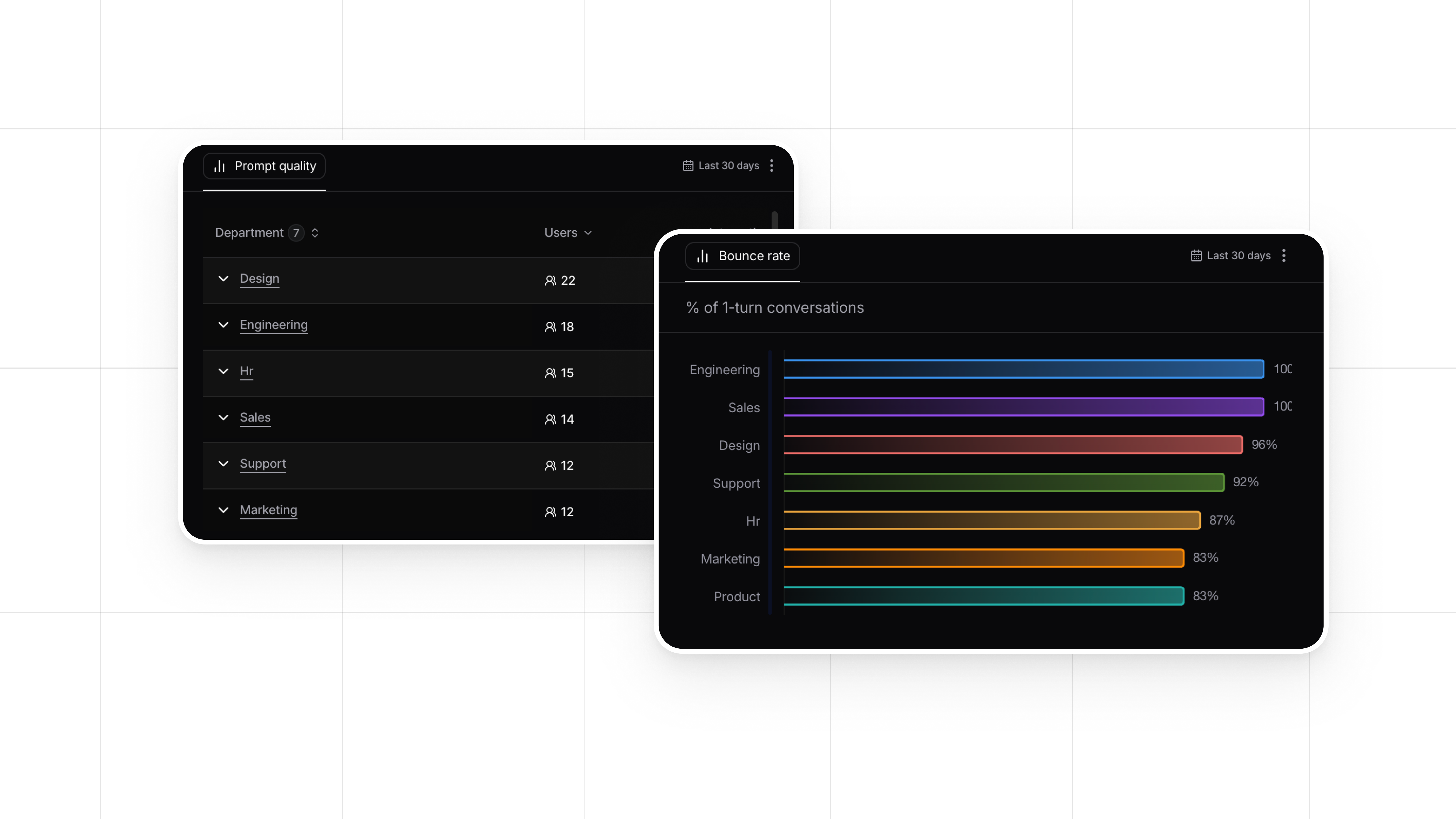
All data is anonymized and aggregated. No individual employee is identified, no conversation is attributed to a specific person. What teams see is fluency at the level that matters for decisions: by department, by role, by tool, over time.
That is the level where interesting things become visible.
A company might discover that one department has high adoption and high fluency, while another has equally high adoption but significantly lower fluency. Same tool, same rollout, different outcomes. That is a signal worth investigating, and it is specific enough to act on.
Or a team might see fluency improving across the board after a training programme, with one tool lagging behind. That is not a people problem. That is a product problem. The tool itself might need better design, better prompts, or better documentation.
The difference between measuring activity and measuring capability
Adoption dashboards answer the question: are people using AI? That is a useful question, but it is only the first one.
AI Fluency Index answers the questions that come after. Are people using AI well? Is their experience improving over time? Where should we invest in enablement next? Is a specific tool pulling its weight, or is it creating friction?
These questions matter because the goal of deploying AI internally is not usage. It is productivity. And productivity depends on how effectively people work with the tools, not just how often they open them.
All of this is measured through anonymized, privacy-safe behavioral signals that are already present in every AI conversation. No new surveys. No self-assessment forms. No changes to the AI tools themselves. Nebuly connects to existing AI products and reads the implicit feedback that employees generate naturally, every time they interact with an AI assistant.
Want to see this in practice? Book a demo with us.